

Ecrit avec amour par :




Dans l'article précédent, nous avons décrit les cinq marqueurs externes qui distinguent, vus de l'extérieur, une auto-réponse aux avis Google qui fait monter un restaurant dans le pack local d'une auto-réponse qui le plombe silencieusement. Cet article-ci change de point de vue. Nous allons décrire l'architecture interne qui produit ces marqueurs, telle que nous l'avons construite et fait tourner chez Dokaa depuis 30 mois de production commerciale sur plus de 700 restaurants en France et à l'international.
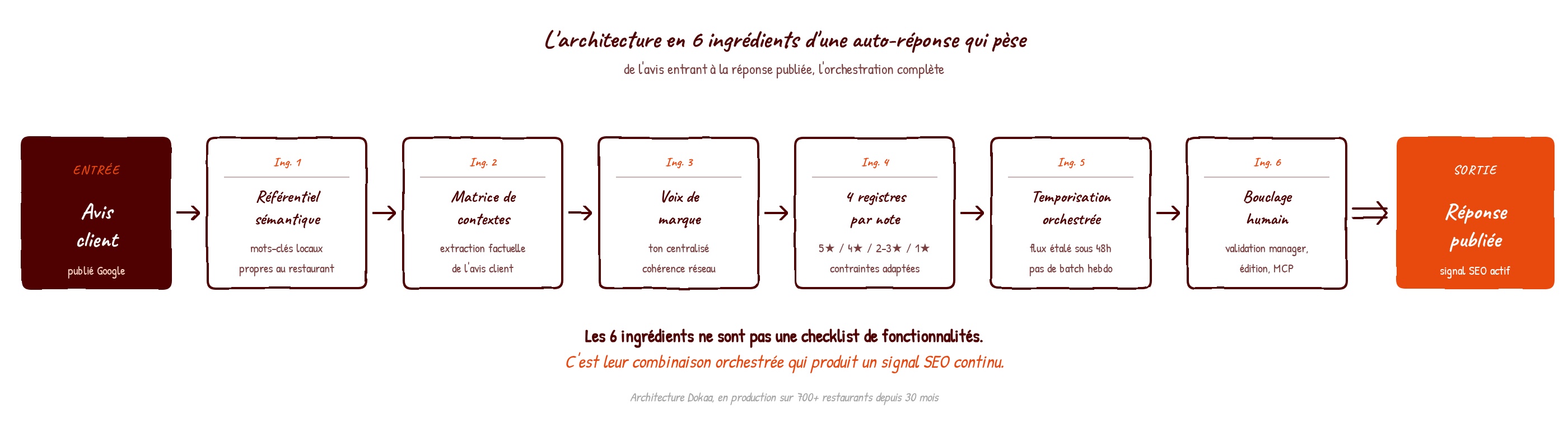
L'idée n'est pas de faire l'apologie d'une solution, mais d'expliquer pourquoi une auto-réponse aux avis n'est pas un produit générique qu'on branche en deux clics, et pourquoi la grande majorité des outils du marché passent à côté de l'essentiel. C'est une orchestration, et cette orchestration repose sur six ingrédients qui doivent être combinés ensemble. Aucun d'entre eux n'est suffisant isolément. C'est leur combinaison qui fait la différence entre un actif SEO continu et une simple validation administrative.
Voici, donc, l'anatomie d'une auto-réponse aux avis qui pèse vraiment en 2026.
Le marché de l'auto-réponse aux avis s'est densifié rapidement sur les 24 derniers mois. Des dizaines de wrappers de modèles génériques sont apparus, la plupart construits sur le même principe : envoyer le texte de l'avis à un LLM, demander une réponse polie, publier le résultat. Ces outils répondent vite, ils ne se trompent pas grossièrement, et leur prix est attractif. Mais ils partagent tous une limite structurelle qui, en 2026, devient un handicap algorithmique majeur.
Sur les 30 mois où nous avons fait tourner notre propre architecture de réponse en production, trois écarts se sont creusés entre les approches "wrapper LLM générique" et les approches qui combinent une vraie architecture :
👉 L'écart sémantique. Une réponse générée par wrapper LLM sans référentiel local injecté produit des formules polies mais vides de mots-clés différenciants. Au bout de 500 réponses, la fiche n'a accumulé aucun signal sémantique exploitable par l'algorithme Google. Au bout de 500 réponses architecturées, la fiche a accumulé des centaines d'occurrences de mots-clés locaux pertinents
👉 L'écart de cohérence. Une réponse générée à chaque appel sans mémoire de la voix de marque, des formules récurrentes ou du contexte cumulé, produit des réponses qui dérivent en registre, en vocabulaire et en structure. Au bout de plusieurs mois, la fiche envoie un signal d'identité diffuse au lieu d'un signal d'entité cohérente
👉 L'écart opérationnel. Un wrapper LLM générique ne sait pas s'intégrer aux systèmes du restaurant (caisse, réservation, livraison) pour contextualiser la réponse avec la commande réelle. Il répond au texte de l'avis pris isolément, sans savoir qu'il s'agit d'une commande Uber Eats à 22h ou d'un déjeuner d'affaires en salle
Ces trois écarts ne se voient pas à court terme, et c'est ce qui rend le sujet pernicieux. Un restaurateur qui branche un wrapper LLM générique a immédiatement 100% de ses avis répondus, et il pense le sujet réglé. Ce qu'il ne voit pas, c'est qu'au bout de six mois, sa fiche n'a pas progressé d'un point dans le pack local, alors qu'un concurrent qui a fait tourner une architecture combinée pendant la même période a pris plusieurs points sur les mêmes requêtes.
L'architecture qui suit est celle que nous avons construite chez Dokaa pour éviter précisément ces trois écarts. Elle repose sur six ingrédients qui doivent fonctionner ensemble.
La règle pratique à retenir sur cette section : un wrapper LLM générique répond, mais ne construit rien. Une architecture orchestrée répond ET accumule un signal sémantique cohérent sur le temps long. La différence ne se voit pas dans la réponse individuelle. Elle se voit dans la fiche au bout de six mois.
Le premier ingrédient est celui qui change le plus radicalement la qualité SEO des réponses produites. Avant qu'une seule réponse soit générée pour un restaurant, nous construisons et maintenons pour ce restaurant un référentiel sémantique propre, qui contient les éléments lexicaux pertinents à injecter dans les réponses.
Ce référentiel se construit en trois temps :
👉 Extraction des mots-clés locaux pertinents. Quartier précis, type de cuisine, occasions typées (afterwork, brunch, anniversaire, déjeuner d'affaires, dîner en groupe), spécificités du lieu (terrasse, cave, four à bois, espace privatif), positionnement éditorial (bistrot, brasserie artisanale, table bistronomique, trattoria de quartier)
👉 Hiérarchisation par valeur SEO. Tous les mots-clés ne se valent pas. Certains sont très recherchés et faiblement concurrentiels (l'occasion croisée à la cuisine et au quartier). D'autres sont saturés et peu différenciants. Le référentiel les pondère pour que les réponses injectent en priorité les termes à plus fort retour
👉 Mise à jour continue. Le référentiel évolue avec les saisons (carte d'été, événements particuliers), avec les changements de positionnement (un restaurant qui ajoute une cave naturelle), et avec les performances observées (un mot-clé qui décolle dans le pack local doit être priorisé dans les réponses suivantes)
Concrètement, pour un restaurant indépendant à Reims dans la restauration brassicole, le référentiel contiendra typiquement 8 à 12 mots-clés actifs ("brasserie artisanale", "afterwork", "bière maison brassée sur place", "anniversaire", "groupe", "carte de saison", "place de la Comédie", etc.). Chaque réponse générée puise dans ce référentiel sans répétition mécanique, en privilégiant les termes que l'avis original suggère naturellement.
C'est ce premier ingrédient qui sépare une auto-réponse "polie" d'une auto-réponse qui pèse en SEO local. Sans référentiel propre au restaurant, les réponses sont génériques, peu importe la qualité du LLM utilisé.
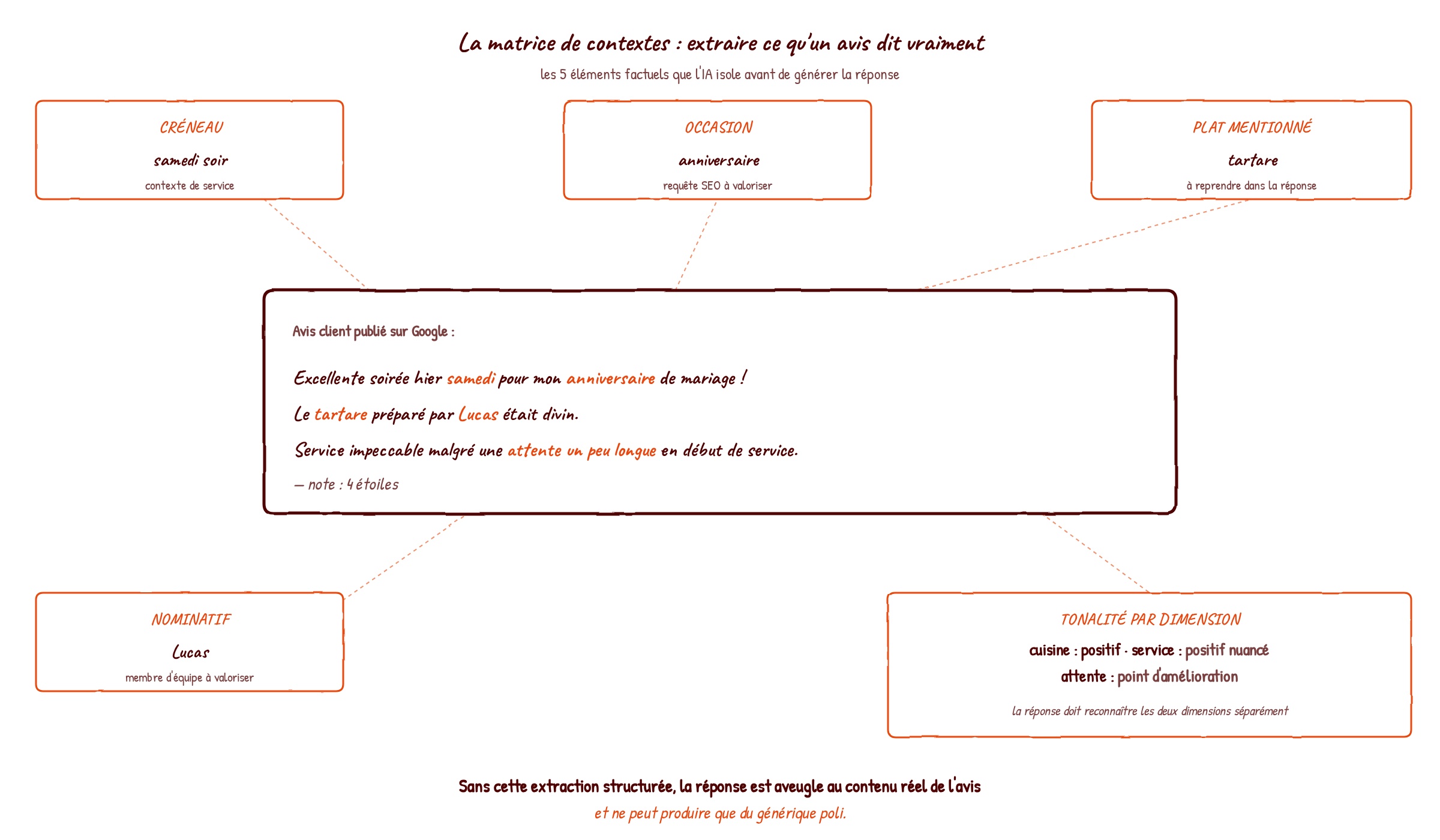
Le deuxième ingrédient s'occupe d'un autre aspect critique : comprendre finement ce que l'avis du client dit, et le restituer dans la réponse de manière non mécanique. C'est ce qui transforme une réponse générique en réponse personnalisée.
Pour chaque avis qui arrive, nous extrayons automatiquement une matrice de contextes :
👉 Le plat ou la prestation mentionnée, quand le client l'a citée. C'est le signal de personnalisation le plus puissant, et c'est aussi le plus utile à reprendre dans la réponse
👉 L'occasion de la visite, quand elle est explicite ou inférable (un "anniversaire", un "déjeuner pro", un "dîner entre amis", un "afterwork"). Cette occasion est une requête SEO en soi, et la reprendre dans la réponse renforce la pertinence sur cette requête
👉 Le créneau ou le contexte de service. Midi, soir, samedi soir, jour férié, livraison, click & collect. Chaque contexte appelle un registre légèrement différent
👉 La mention nominative d'un serveur, d'un cuisinier ou d'un membre d'équipe, quand le client la fait. C'est un signal critique à ne jamais perdre, et à valoriser dans la réponse
👉 La tonalité par dimension. Un avis 4 étoiles peut être positif sur la cuisine et négatif sur le service, ou inversement. La réponse doit reconnaître les deux séparément, pas se contenter de la note globale
Cette extraction n'est pas une réécriture du texte de l'avis. C'est une lecture structurée, qui produit une matrice de cinq à six éléments factuels que la génération de réponse peut ensuite mobiliser. Sans cette matrice, la réponse est aveugle au contenu réel de l'avis et ne peut produire que du générique poli.
Le troisième ingrédient devient critique dès qu'on dépasse l'établissement isolé. Un groupe de 10 ou 80 restaurants ne peut pas se permettre que ses 500 réponses mensuelles soient rédigées dans des registres différents selon les opérateurs locaux. La cohérence de marque doit être tenue centralement, sans étouffer la personnalisation locale qui fait la qualité de chaque réponse.
L'architecture de voix de marque centralisée chez Dokaa repose sur trois niveaux d'autorité :
👉 Niveau siège : le ton et les invariants. La direction marketing du siège définit le registre (vouvoiement ou tutoiement), les formules d'ouverture et de clôture autorisées, le vocabulaire de marque récurrent ("notre maison", "votre table", "nos plats du moment"), et les éléments à ne jamais mentionner (tarifs précis, comparaisons concurrents, promesses)
👉 Niveau établissement : le référentiel local. Chaque restaurant du réseau a son propre référentiel sémantique (cf. ingrédient 1) qui contient les mots-clés du quartier, la spécificité du lieu, les noms des serveurs, les plats phares de l'année
👉 Niveau opérationnel : la personnalisation par avis. La matrice de contextes (cf. ingrédient 2) extrait pour chaque avis les éléments factuels à reprendre. Cette personnalisation s'opère sous contrainte des deux niveaux précédents
L'orchestration entre ces trois niveaux est ce qui permet d'avoir, à la fois, une voix de marque parfaitement cohérente sur 500 réponses mensuelles d'un réseau de 10 restaurants, ET une personnalisation locale fine pour chaque avis. Sans cette orchestration, le réseau se retrouve avec deux options également mauvaises : soit toutes les réponses sortent du même moule générique (signal d'identité diffuse), soit chaque manager local rédige à sa manière (incohérence de marque à travers le réseau).
Le quatrième ingrédient adapte la réponse au contenu émotionnel de l'avis. Une réponse identique à un avis 5 étoiles enthousiaste et à un avis 1 étoile critique est immédiatement repérable, à la fois par les futurs lecteurs et par les algorithmes qui détectent les patterns de standardisation excessive.
Notre architecture distingue quatre registres de réponse, qui ont chacun leurs contraintes spécifiques :
👉 Registre 5 étoiles enthousiaste. Réponse chaleureuse, qui valorise sans s'effacer, qui glisse un ou deux mots-clés locaux pertinents, qui n'oublie pas de remercier la personne nominativement quand c'est possible, et qui invite implicitement à revenir
👉 Registre 4 étoiles nuancé. Réponse qui reconnaît la satisfaction globale ET le point d'amélioration cité, qui apporte une explication factuelle quand pertinente, et qui invite à revenir tester l'amélioration. C'est paradoxalement le registre le plus pédagogique pour les futurs lecteurs
👉 Registre 2-3 étoiles mitigé. Réponse qui prend au sérieux la critique sans se défendre, qui propose un canal direct pour creuser, et qui montre au futur lecteur la maturité du restaurant face à une critique structurée
👉 Registre 1 étoile dur ou injuste. Réponse posée, factuelle, qui rectifie sans agresser, qui propose une suite, et qui démontre au futur lecteur que le restaurant sait gérer la critique. C'est le registre où une mauvaise réponse fait plus de dégâts que l'avis lui-même
Ces quatre registres ne sont pas des templates rigides. Ils définissent des contraintes de structure et de ton dans lesquelles la génération opère, en combinaison avec le référentiel sémantique, la voix de marque et la matrice de contextes des trois ingrédients précédents.
Le cinquième ingrédient s'occupe d'un aspect que la plupart des outils négligent complètement : à quel moment exact publier la réponse. Un système qui surveille la fiche en continu et déclenche la rédaction au fil de l'arrivée des avis produit un signal très différent d'un système qui répond en batch hebdomadaire.
Notre architecture orchestre la temporisation autour de quatre règles :
👉 Détection en quasi-temps réel des nouveaux avis sur l'ensemble des plateformes connectées. Une fenêtre de quelques heures sépare la publication de l'avis et le déclenchement de la rédaction
👉 Délai de publication étalé sur les heures qui suivent, pas en lot le lendemain matin. Un avis publié à 23h verra sa réponse arriver entre 8h et 11h le matin suivant, jamais à 9h pile pour 50 avis en même temps
👉 Priorisation des avis difficiles. Un avis 1 ou 2 étoiles déclenche une rédaction prioritaire, avec un délai cible sous 24 heures. La rapidité de réaction sur les avis difficiles est un signal de professionnalisme lu à la fois par les futurs lecteurs et par l'algorithme
👉 Lissage hebdomadaire. Pas plus de réponses publiées un lundi qu'un mercredi, à volume d'avis comparable. Une fiche dont 80% des réponses sont publiées en début de semaine envoie un signal de processus impersonnel, par opposition à une fiche dont les réponses sont étalées sur les sept jours
Cette temporisation est invisible pour le restaurateur, mais elle est lue finement par l'algorithme et par les futurs lecteurs qui parcourent les avis récents. Une fiche qui répond en flux continu paraît vivante. Une fiche qui répond en batch paraît automatisée par un prestataire externe, ce qui dégrade les deux signaux à la fois.
Le sixième et dernier ingrédient est celui qui empêche le système de devenir aveugle à lui-même. Aussi sophistiquée soit l'architecture des cinq ingrédients précédents, elle ne remplace pas le pilotage humain. Elle le rend disponible et utile, là où sans architecture, le pilotage humain est noyé sous le volume.
Notre architecture donne au manager local et au siège quatre points d'entrée :
👉 La validation a priori des avis sensibles. Pour les avis 1 et 2 étoiles, la réponse générée est proposée en brouillon au manager local, qui peut valider, éditer ou réécrire avant publication. Ce contrôle préserve la qualité du moment le plus critique du cycle
👉 L'édition des réponses publiées. Toute réponse publiée reste éditable pendant 48 heures, au cas où un manager voit passer un détail à ajuster ou un mot-clé à corriger. Cette possibilité de retouche évite que l'auto-réponse devienne un dispositif rigide
👉 Le pilotage par dashboard. Le manager local et le siège ont accès à une lecture des réponses générées et de leurs caractéristiques (taux de personnalisation factuelle, densité de mots-clés locaux, délai de publication moyen, distribution par note). Cette lecture continue permet d'ajuster le référentiel et la voix de marque dans le temps
👉 L'analyse via le MCP. Pour les questions ad-hoc qui sortent des dashboards par défaut ("sors-moi toutes les réponses qui mentionnent le brunch sur les 3 derniers mois et leur impact sur le classement local"), le manager peut interroger directement les données en langage naturel via le MCP Dokaa, sans avoir à passer par le support
Ce bouclage humain est ce qui transforme une auto-réponse "à l'aveugle" en outil opérationnel piloté. C'est aussi ce qui permet à l'architecture de s'améliorer dans le temps : chaque édition humaine est un signal d'apprentissage pour le système.
La règle pratique à retenir sur l'ensemble des six ingrédients : aucun d'entre eux n'est suffisant isolément. Un référentiel sans matrice de contextes produit des réponses lourdes en mots-clés mais déconnectées de l'avis. Une matrice de contextes sans voix de marque produit des réponses personnalisées mais incohérentes en réseau. Une voix de marque sans bouclage humain produit un système rigide qui dérive. C'est la combinaison des six qui fait le signal SEO, pas la somme des fonctionnalités prises séparément.
Pour comprendre les marqueurs externes que cette architecture vise à produire, lisez l'article complémentaire Réponses aux avis Google en 2026 : pourquoi le contenu de votre réponse pèse désormais autant que la note moyenne. Pour creuser ce que l'IA change plus globalement dans la mécanique des avis, lisez ce que l'IA change concrètement pour vos avis Google en 2026. Et pour le pilotage opérationnel via le MCP évoqué en ingrédient 6, lisez comment exploiter vos avis clients pour piloter votre activité.
Le marché de l'auto-réponse aux avis a beaucoup parlé de productivité ces dernières années. La promesse était simple : un outil qui répond à votre place, vous gagnez du temps. Cette promesse a été tenue par la plupart des solutions. Mais elle s'est révélée être la mauvaise promesse pour 2026. Le sujet n'est plus la productivité, c'est l'architecture du signal SEO que vos réponses construisent dans le temps.
Les six ingrédients décrits dans cet article ne sont pas une checklist de fonctionnalités. Ils sont une orchestration, et c'est cette orchestration qui décide si vos réponses cumulent un signal SEO actif sur 6 à 18 mois, ou si elles n'apportent qu'une validation administrative. Aucun outil sérieux du marché ne combine aujourd'hui ces six dimensions ensemble. Chez Dokaa, c'est précisément ce que nous avons construit, raffiné et fait tourner sur 30 mois et 700+ restaurants.
L'écart avec un wrapper LLM générique ne se voit pas le premier mois. Il se voit dans le classement local au bout de six mois, dans l'évolution de la note moyenne au bout de douze mois, et dans la marge nette au bout de dix-huit mois. C'est la mécanique cumulative décrite dans nos articles précédents sur la chaîne visibilité-marge, appliquée spécifiquement au levier de la réponse aux avis.
Si vous voulez voir comment cette architecture produirait des réponses sur votre propre restaurant, nous proposons un audit gratuit qui analyse vos 50 dernières réponses, identifie les écarts avec les six ingrédients ci-dessus, et vous montre concrètement la différence de signal SEO entre votre dispositif actuel et une auto-réponse architecturée. Sans engagement, sans installation à faire.